MySQL 高可用架构体系
MySQL 高可用架构体系
Section titled “MySQL 高可用架构体系”在实际生产环境中,数据库系统往往是整个应用架构中最核心也是最脆弱的一环。如果数据库出现单点故障,哪怕整个系统的应用层部署得再多副本,业务依然可能因为无法写入或读取关键数据而全面瘫痪。
早期架构中,数据库大多采用单实例部署,随着并发量上升和可用性要求提升,逐渐演化出主从复制、读写分离等方式来分担压力。然而,传统的主从架构在面对数据库主库故障时,往往需要依赖人工干预进行主备切换,存在响应慢、切换不彻底、业务中断等问题。
尤其在以下这些场景下,传统方案的局限性会被无限放大:
- 核心交易链路要求秒级主备切换,不能容忍业务长时间阻塞;
- 数据访问链路复杂,需要自动感知主从拓扑变化;
- 对一致性要求高,不能容忍复制延迟带来的读写不一致;
- 多数据中心部署,需要考虑跨机房故障切换与连接调度。
为了解决这些问题,现代 MySQL 架构引入了三种具有代表性的高可用方案,分别从复制机制、代理控制、集群协调等层面出发,构建出更加健壮、可自动切换的数据库系统:
- PXC 架构:基于 Percona XtraDB Cluster 实现的 同步多主复制 集群,强调节点间数据一致性与写入可靠性,适用于对一致性要求极高的业务场景。
- QMHA 架构:作为数据库访问的 代理与高可用切换组件,构建于传统 MySQL 主从之上,提供读写分离、连接路由和主备故障自动切换能力。
- 3M 架构:由 Meta、Monitor、Manager 组成的 数据库主从状态控制体系,配合 QMHA 实现主从感知、健康监控与主库选举切换的自动化能力。
这三种架构可以单独使用,也可以按需组合搭建,满足不同业务对数据库可用性、一致性、访问灵活性的综合要求。
接下来的内容将围绕这三种架构展开,介绍它们的设计思路、同步模型、优缺点与适用场景,帮助你深入理解现代数据库高可用体系的核心原理。

3M 架构:曾经经典,如今逐步被淘汰的高可用方案
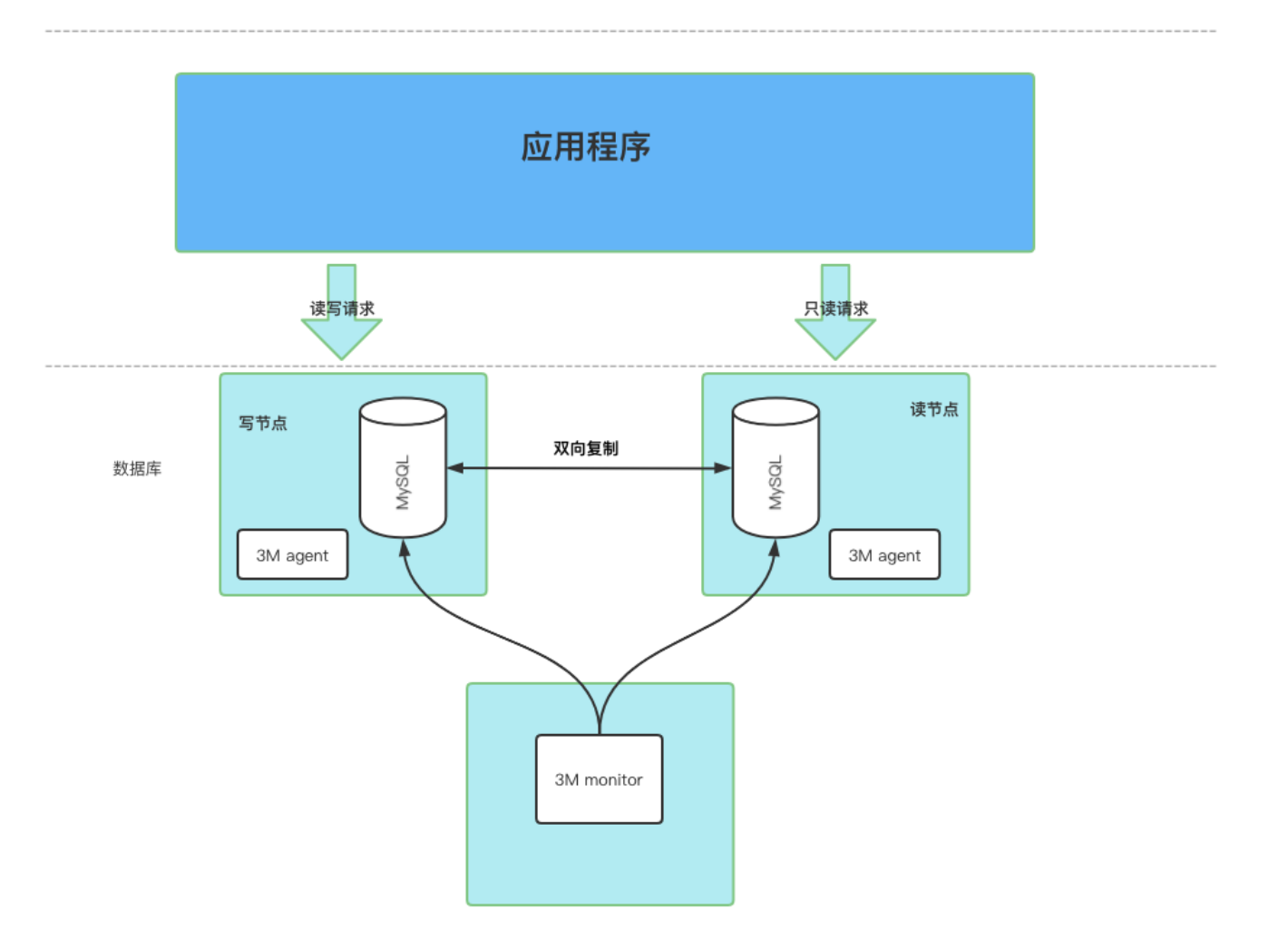
Section titled “3M 架构:曾经经典,如今逐步被淘汰的高可用方案”3M 架构是早期主从数据库系统中广泛应用的一套高可用方案,它的核心由三个角色组成:Monitor、Agent 和 VIP。整体思路非常直接:Monitor 负责探活和切换决策,Agent 接收指令并执行切换动作,而 VIP(虚拟 IP)作为数据库的统一访问入口,确保应用连接不受主从变更的影响。
架构工作机制简述
Section titled “架构工作机制简述”在 3M 架构下,数据库通常部署为一主一从(或多从)的结构。Monitor 节点周期性地检测数据库的可用性,一旦发现主库不可用,就会自动发起主备切换流程,指定一个健康的从库为新主库。与此同时,它会将切换指令下发给对应的 Agent。
Agent 部署在数据库机器上,负责执行网络层的 VIP 迁移操作。写 VIP 始终绑定在当前主库节点上,所有应用的写请求都通过它发起。而读 VIP 则通常绑定在一个或多个从库节点上,用于分担只读流量,实现读写分离。这样应用程序始终通过 VIP + PORT 的方式访问数据库,无需感知主从切换的过程,具备一定程度上的“连接透明性”。
主从同步方式
Section titled “主从同步方式”在 3M 架构中,数据库仍采用的是 传统的 MySQL 异步主从复制机制,即主库通过 binlog(日志)将写入操作推送到从库,从库通过 I/O 线程与 SQL 线程进行拉取与回放,达到数据同步目的。虽然这种同步方式部署简单、写性能好,但它也引入了 3M 架构本身无法规避的一些问题: 主从延迟,读写数据可能不一致; 切主过程可能导致数据不完整。
为什么 3M 架构逐步被废弃?
Section titled “为什么 3M 架构逐步被废弃?”尽管 3M 架构在早期解决了主从切换依赖人工、应用需手动调整连接的问题,但它存在几个 关键性缺陷,导致它逐步被更先进的方案所取代:
1. 无法支持跨机房容灾
3M 架构依赖 VIP 技术来漂移数据库访问地址,而 VIP 本质上是一种基于局域网(Layer 2)的虚拟网络接口,只能在同一个物理网络内生效。一旦数据库节点部署在多个机房,VIP 就无法在机房之间漂移,也就失去了切主的能力。
所谓容灾,指的是当一整个数据中心或某个地域的资源不可用时,系统仍能在其他地点继续提供服务。3M 架构由于无法漂移 VIP 到异地节点,意味着只要主机房断网或断电,应用就无法通过 VIP 连接新主库,整个系统将陷入不可用状态。这一点是其架构上的硬伤。
2. 对网络与运维依赖强
VIP 漂移操作依赖底层网络环境支持,如 ARP 抢占、心跳广播、路由刷新等,需要较高权限的系统操作,并对网络配置有较强依赖。Agent 通常需要使用 ifconfig 或 ip 命令管理接口,存在一定安全与稳定性风险。
同时,网络延迟、漂移失败、绑定卡顿等问题可能导致“切主成功但连接仍在旧主”的脏状态,影响系统稳定性。
3. 扩展性差,不适应分布式架构
随着服务从单体向分布式演进,数据库也逐渐部署在多个 IDC、混合云、容器环境中。此时依赖物理 VIP 的访问方式变得不再适用。3M 架构在本质上是为“单机房物理部署”设计的,不具备服务发现、弹性接入、多副本调度等现代能力。
QMHA 架构:基于代理与服务发现的现代高可用方案
Section titled “QMHA 架构:基于代理与服务发现的现代高可用方案”为了解决传统主从架构中主备切换依赖底层网络(如 VIP 漂移)、无法跨机房容灾等问题,QMHA 架构应运而生。它以逻辑代理 + 中心化调度 + namespace 路由机制为核心设计,彻底摆脱了对物理网络和静态连接方式的依赖,具备更好的可扩展性、灵活性与多环境适配能力。
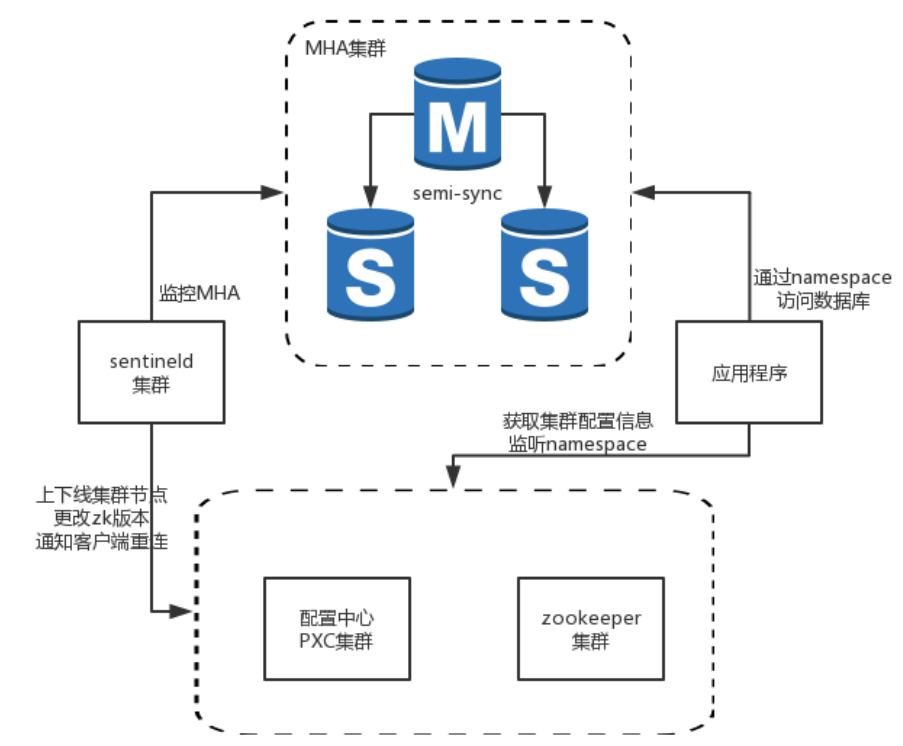
与 3M 不同,QMHA 并不是直接操作数据库节点的网络接口来实现切换,而是通过独立部署的一组 哨兵节点(sentinel) 来持续监控数据库集群中的所有 MySQL 实例。这些哨兵之间会相互通信、比对状态,判断当前主库是否存活,并在主库故障时发起主从切换。同时,哨兵会将最新的集群信息写入配置中心(如 ZooKeeper),并实时刷新与之绑定的 namespace 映射关系。
应用程序访问数据库时,不再通过 IP + 端口直连,而是通过逻辑名(namespace)接入。QMHA 会根据 namespace 的角色配置,将请求路由到当前的主节点(write)或从节点(read),实现动态读写分离与无感切主。如下图所示,主从之间使用半同步复制保证一定的复制实时性,而 QMHA 负责保障连接稳定、角色正确。
应用接入与节点角色说明
Section titled “应用接入与节点角色说明”从实际的运维界面来看,一个数据库集群在 QMHA 中通常会绑定一个唯一的 namespace,例如 dba_callcenter_online。这个 namespace 下的节点被划分为不同的角色:
- write 节点:可读可写,所有涉及写操作的业务必须通过 write 节点接入。QMHA 确保其始终指向当前主库;
- read 节点:只读节点,供只读请求使用,不具备写权限,通常绑定从库;
- Statistic 节点:也称为“静态节点”或“离线节点”,仅供数据平台或 BI 等统计型业务使用,需通过 IP+Port 方式访问,不参与主备切换和高可用保障。
这种通过 namespace 做逻辑接入、通过角色分类做精细路由的方式,极大提升了数据库访问的可控性。无论数据库发生主从切换、迁移还是下线,应用端都无需改动配置,只要 namespace 保持不变,路由策略就能自动适配。
高可用机制与优势分析
Section titled “高可用机制与优势分析”QMHA 架构采用的是 半同步主从复制机制,即主库在写入事务时会等待至少一个从库 ack 确认后再提交,兼顾了性能与数据安全。而主从切换由哨兵节点统一协调,配置中心持久化元信息,路由层监听 namespace 实时更新,整个系统具备如下优势:
- 支持跨机房容灾 QMHA 不依赖网络层 VIP 漂移,因此可以部署在多个数据中心之间。哨兵和 ZooKeeper 可实现跨地域协作,当主库所在机房故障时,从库在异地也能被迅速提为主库,并更新 namespace 指向,应用无感切换。
- 连接逻辑解耦,运维成本低 应用只需关注 namespace,不再需要绑定具体 IP 或节点名,数据库节点的上下线、扩容、角色变化都可以在后台自动完成,无需业务介入。
- 读写分离灵活可控 QMHA 会根据节点角色自动路由 SQL 请求。写请求只发送到 write 节点,读请求可以分摊给多个 read 节点。相比 3M 架构中只能通过静态 VIP 实现简单读写分离,这种方式更加智能和稳定。
- 状态可观测,界面化配置清晰 管理控制台支持查看每个 namespace 下的集群状态、角色分配、节点版本、复制关系等信息,对于问题排查和容量管理非常直观高效。
PXC 架构:强一致性的同步多主集群方案
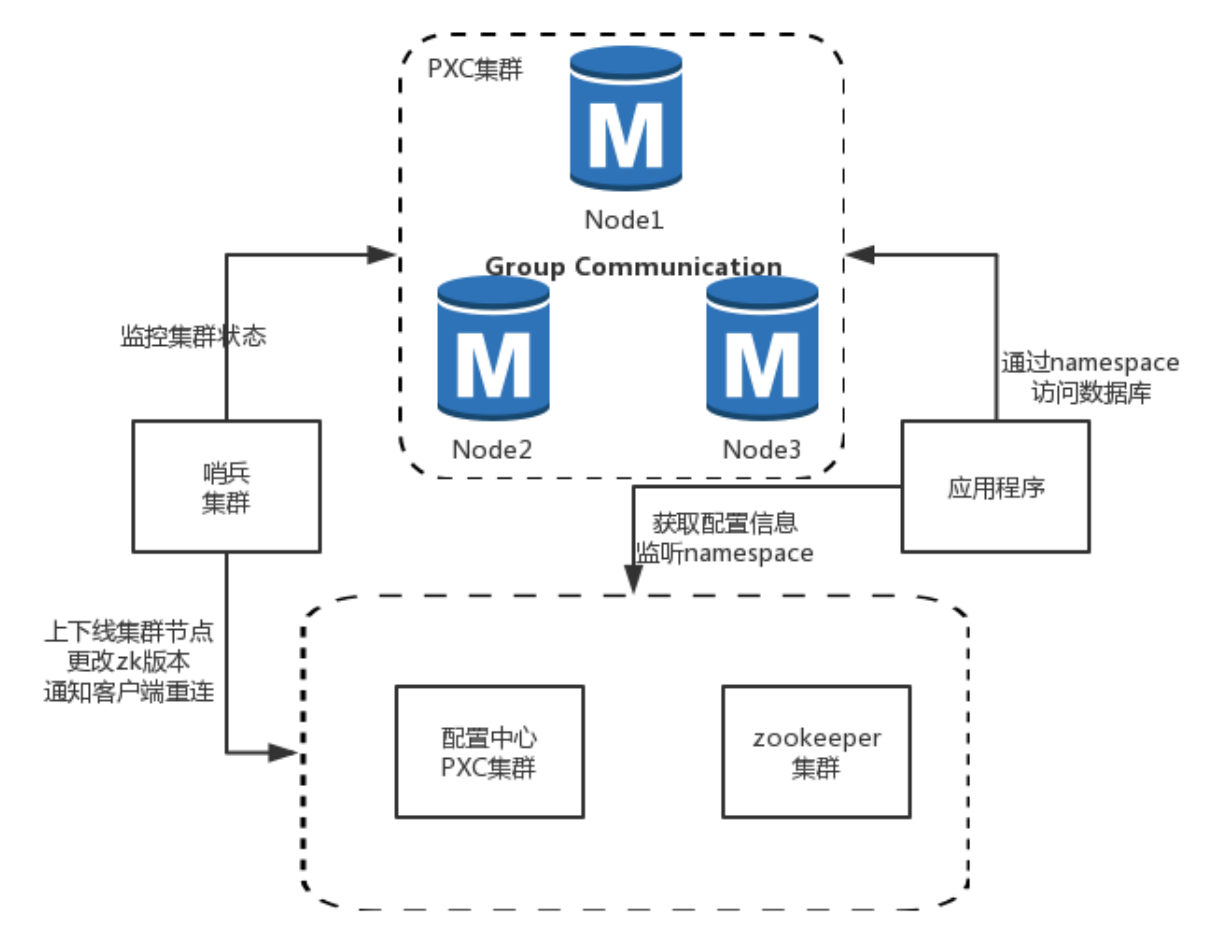
Section titled “PXC 架构:强一致性的同步多主集群方案”PXC(Percona XtraDB Cluster)架构是基于 Galera 协议实现的一种 同步多主 MySQL 集群,相比于传统的主从复制,它在高可用与一致性保障方面提供了更高等级的能力。其核心思想是将多个 MySQL 实例组建为一个对等的集群,所有节点都处于相同状态,通过 组通信协议(Group Communication) 实现写操作同步复制,从而保证每个事务在多个节点上同时生效。
在 PXC 架构中,所有节点均为主节点(M),都可接收读写请求,但为了简化业务侧行为,实际部署中仍常采用“主写从读”的方式,即明确区分 write 节点和 read 节点,由代理层进行路由转发。每个节点的角色信息与可用状态由哨兵组件持续监控,并将状态变化同步到 ZooKeeper 等配置中心。应用程序依然是通过 namespace 接入数据库,避免了绑定物理地址的局限性,也支持灵活的切主与节点替换。
数据一致性保障机制
Section titled “数据一致性保障机制”PXC 架构的核心在于它采用了 同步复制 模式。在每一次事务提交之前,写请求会广播给集群内所有节点,并等待它们返回一致性认证(certification)的确认,只有全部节点通过认证后,该事务才会正式在当前节点提交。这意味着:
- 数据变更在集群中是一致的,不存在“写成功但从库尚未同步”的读写不一致问题;
- 主备切换过程中,不存在 binlog 漏同步等数据丢失隐患;
- 新节点加入时也会通过 SST(State Snapshot Transfer)或 IST 自动补齐数据。
这一特性极大提升了 PXC 架构的可靠性,但也带来了同步复制天然的性能瓶颈,尤其在高并发大事务场景下,性能可能会受到较大影响。
应用接入与节点角色划分
Section titled “应用接入与节点角色划分”与 QMHA 相同,PXC 集群在逻辑接入上也通过 namespace 抽象,集群中的节点被标记为不同角色:
- write 节点:即便所有节点都可写,但为了集中写负载和避免冲突,生产环境通常只暴露一个 write 节点给有写操作的应用接入;
- read 节点:提供只读能力,由代理层或中间件将查询请求路由至这些节点,减轻主节点压力;
- Statistic 节点:用于数据平台或分析类任务,只允许通过 IP+Port 接入,不受高可用保障,适用于离线统计类查询。
这种划分方式可以实现业务侧的高可用、读写分离以及多租户的资源隔离管理。
使用限制与注意事项
Section titled “使用限制与注意事项”尽管 PXC 架构在一致性方面表现优异,但由于同步复制的特性,也存在一些使用限制:
- 不适合大事务 由于事务提交前需要广播并等待所有节点认证确认,大事务(如大表更新、批量插入)会显著拉长响应时间,甚至导致整个集群性能抖动。
- 不适合慢查询或统计查询 慢 SQL 尤其是大表 Join、聚合等操作会拖慢事务认证和数据传播,一个节点的慢查询可能阻塞整个集群的写入能力,因此 PXC 通常不推荐直接承载复杂分析型查询。
- 节点数量受限,建议奇数节点部署 为保障仲裁机制和数据一致性,推荐节点数为奇数(通常是 3 或 5),以防止脑裂或选主失败。
架构对比总结:如何选择适合自己的高可用方案?
Section titled “架构对比总结:如何选择适合自己的高可用方案?”通过以上介绍,我们已经分别分析了 3M、QMHA 和 PXC 三种主流的 MySQL 高可用架构。为了更直观地展示它们之间的差异,下表对三者的核心能力进行了总结归纳:
| 能力项 | 3M | QMHA | PXC |
|---|---|---|---|
| 读写分离 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
| 一致性保障 | 异步复制,最终一致 | 半同步复制,可保证主库数据不丢失 | 强一致性,同步复制 |
| 故障自动转移 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
| 切主影响 | 会短暂只读 | 会短暂只读 | 几乎无感知 |
| 管理方式 | 单点控制 | 分布式哨兵 + 配置中心 | 分布式仲裁 + 哨兵 |
结合上表可以看出:
- 3M 架构适合小规模、单机房部署,改造成本低,但局限在异步复制机制下,存在一致性与容灾能力不足的问题。
- QMHA 架构具备较强的灵活性与可维护性,是当前主流高可用代理架构,支持跨机房容灾、读写分离和分布式调度,适合大多数业务系统作为首选。
- PXC 架构则更适用于核心交易类场景,对数据一致性有强依赖的系统,例如支付、订单、账户系统等,但需注意其写性能瓶颈与慢查询的集群级影响。
推荐选型建议:
Section titled “推荐选型建议:”| 业务场景 | 建议架构 |
|---|---|
| 轻量级服务、部署在同一机房 | ✅ 3M(历史方案) |
| 电商、内容、搜索、通用服务系统 | ✅ QMHA(默认方案) |
| 金融、交易、订单核心系统 | ✅ PXC(高一致性场景) |